This post takes a look at the speed - latency and throughput - of various subsystems in a modern commodity PC, an Intel Core 2 Duo at 3.0GHz. I hope to give a feel for the relative speed of each component and a cheatsheet for back-of-the-envelope performance calculations. I've tried to show real-world throughputs (the sources are posted as a comment) rather than theoretical maximums. Time units are nanoseconds (ns, 10-9 seconds), milliseconds (ms, 10-3 seconds), and seconds (s). Throughput units are in megabytes and gigabytes per second. Let's start with CPU and memory, the north of the northbridge:
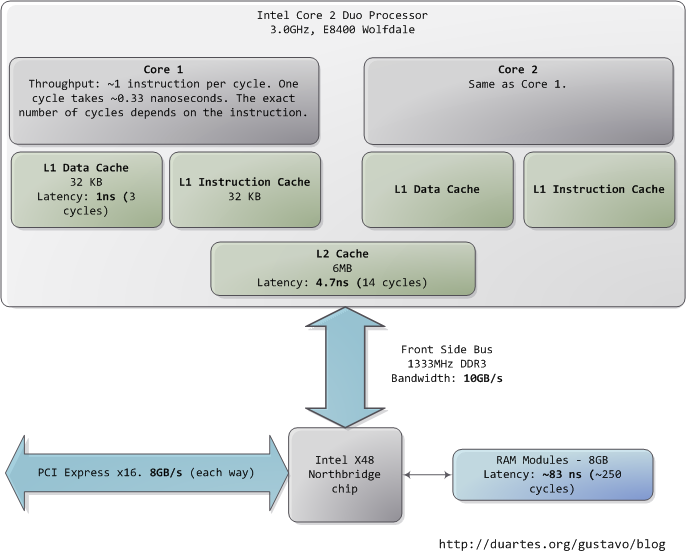
The first thing that jumps out is how absurdly fast our processors are. Most simple instructions on the Core 2 take one clock cycle to execute, hence a third of a nanosecond at 3.0Ghz. For reference, light only travels ~4 inches (10 cm) in the time taken by a clock cycle. It's worth keeping this in mind when you're thinking of optimization - instructions are comically cheap to execute nowadays.
As the CPU works away, it must read from and write to system memory, which it accesses via the L1 and L2 caches. The caches use static RAM, a much faster (and expensive) type of memory than the DRAM memory used as the main system memory. The caches are part of the processor itself and for the pricier memory we get very low latency. One way in which instruction-level optimization is still very relevant is code size. Due to caching, there can be massive performance differences between code that fits wholly into the L1/L2 caches and code that needs to be marshalled into and out of the caches as it executes.
Normally when the CPU needs to touch the contents of a memory region they must either be in the L1/L2 caches already or be brought in from the main system memory. Here we see our first major hit, a massive ~250 cycles of latency that often leads to a stall, when the CPU has no work to do while it waits. To put this into perspective, reading from L1 cache is like grabbing a piece of paper from your desk (3 seconds), L2 cache is picking up a book from a nearby shelf (14 seconds), and main system memory is taking a 4-minute walk down the hall to buy a Twix bar.
The exact latency of main memory is variable and depends on the application and many other factors. For example, it depends on the CAS latency and specifications of the actual RAM stick that is in the computer. It also depends on how successful the processor is at prefetching - guessing which parts of memory will be needed based on the code that is executing and having them brought into the caches ahead of time.
Looking at L1/L2 cache performance versus main memory performance, it is clear how much there is to gain from larger L2 caches and from applications designed to use it well. For a discussion of all things memory, see Ulrich Drepper's What Every Programmer Should Know About Memory (pdf), a fine paper on the subject.
People refer to the bottleneck between CPU and memory as the von Neumann bottleneck. Now, the front side bus bandwidth, ~10GB/s, actually looks decent. At that rate, you could read all of 8GB of system memory in less than one second or read 100 bytes in 10ns. Sadly this throughput is a theoretical maximum (unlike most others in the diagram) and cannot be achieved due to delays in the main RAM circuitry. Many discrete wait periods are required when accessing memory. The electrical protocol for access calls for delays after a memory row is selected, after a column is selected, before data can be read reliably, and so on. The use of capacitors calls for periodic refreshes of the data stored in memory lest some bits get corrupted, which adds further overhead. Certain consecutive memory accesses may happen more quickly but there are still delays, and more so for random access. Latency is always present.
Down in the southbridge we have a number of other buses (e.g., PCIe, USB) and peripherals connected:
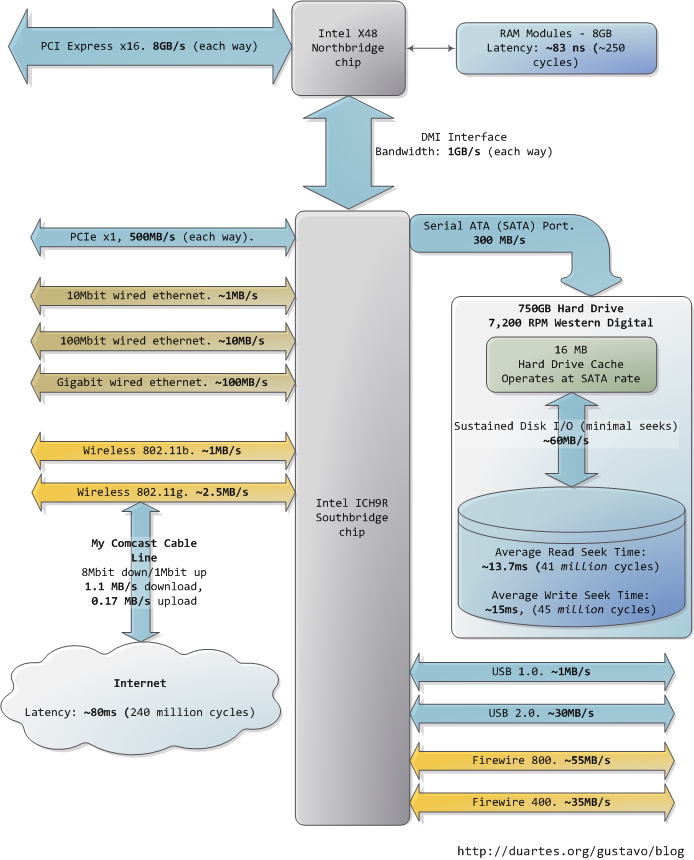
Sadly the southbridge hosts some truly sluggish performers, for even main memory is blazing fast compared to hard drives. Keeping with the office analogy, waiting for a hard drive seek is like leaving the building to roam the earth for one year and three months. This is why so many workloads are dominated by disk I/O and why database performance can drive off a cliff once the in-memory buffers are exhausted. It is also why plentiful RAM (for buffering) and fast hard drives are so important for overall system performance.
While the "sustained" disk throughput is real in the sense that it is actually achieved by the disk in real-world situations, it does not tell the whole story. The bane of disk performance are seeks, which involve moving the read/write heads across the platter to the right track and then waiting for the platter to spin around to the right position so that the desired sector can be read. Disk RPMs refer to the speed of rotation of the platters: the faster the RPMs, the less time you wait on average for the rotation to give you the desired sector, hence higher RPMs mean faster disks. A cool place to read about the impact of seeks is the paper where a couple of Stanford grad students describe the Anatomy of a Large-Scale Hypertextual Web Search Engine (pdf).
When the disk is reading one large continuous file it achieves greater sustained read speeds due to the lack of seeks. Filesystem defragmentation aims to keep files in continuous chunks on the disk to minimize seeks and boost throughput. When it comes to how fast a computer feels, sustained throughput is less important than seek times and the number of random I/O operations (reads/writes) that a disk can do per time unit. Solid state disks can make for a great option here.
Hard drive caches also help performance. Their tiny size - a 16MB cache in a 750GB drive covers only 0.002% of the disk - suggest they're useless, but in reality their contribution is allowing a disk to queue up writes and then perform them in one bunch, thereby allowing the disk to plan the order of the writes in a way that - surprise - minimizes seeks. Reads can also be grouped in this way for performance, and both the OS and the drive firmware engage in these optimizations.
Finally, the diagram has various real-world throughputs for networking and other buses. Firewire is shown for reference but is not available natively in the Intel X48 chipset. It's fun to think of the Internet as a computer bus. The latency to a fast website (say, google.com) is about 45ms, comparable to hard drive seek latency. In fact, while hard drives are 5 orders of magnitude removed from main memory, they're in the same magnitude as the Internet. Residential bandwidth still lags behind that of sustained hard drive reads, but the 'network is the computer' in a pretty literal sense now. What happens when the Internet is faster than a hard drive?
I hope this diagram is useful. It's fascinating for me to look at all these numbers together and see how far we've come. Sources are posted as a comment. I posted a full diagram showing both north and south bridges here if you're interested.