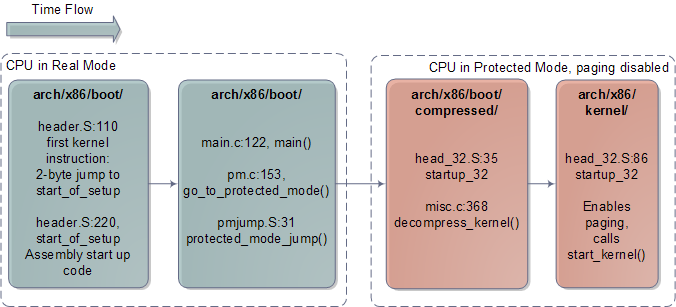
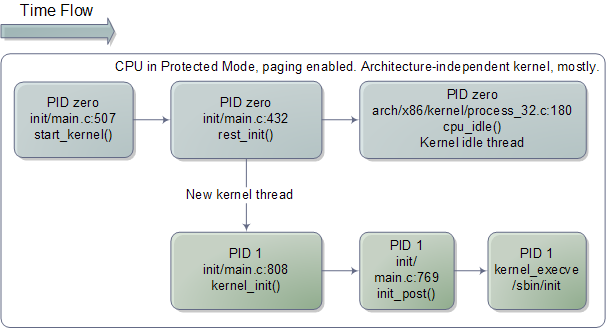
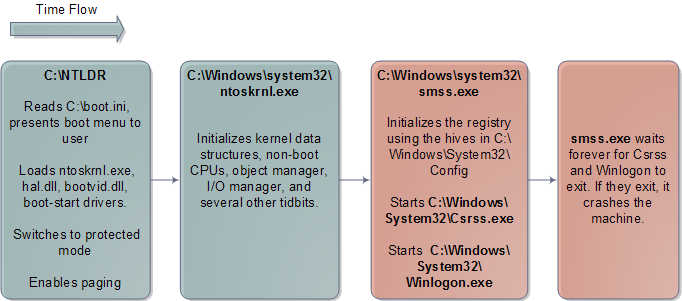
When I was 18 and newly arrived in the US, I used to wonder around enjoying new features like the rule of law and great libraries everywhere. Once while bumming out in North Denver I went into the Regis University library determined to read about physics. I had tried that once before, back in my high school, with poor results. As a teenager I had been obsessed with "understanding" physics and chemistry, especially atomic and quantum theory. I didn't know enough math to study the subjects deeply, but I wanted a conceptual grasp, however incomplete, that was at least half-way consistent and clear.
My high school books and classes left me with the strong feeling that I simply did not get physics. Try as I might, I could not accept the bizarre results of quantum mechanics, wave-particle duality, or how Heisenberg's uncertainty principle could even be science. I was baffled. When I brought it up with teachers, they had ready-made analogies to "teach" what happened in this sub-atomic world. "Think of the solar system," "think of springs connected to each other," "well, it's like this, suppose you have..." These analogies didn't help at all. "You think too concretely, that's why you can't visualize it," told me a teacher.
So I'd sit there and try things, think nonverbally, think in wild shapes, somehow think differently to see if I could imagine a sub-atomic particle and "get it." No go. I wondered whether programming had perhaps damaged my mind by making it inflexible. I went to the school library and found a more advanced physics book, a bit tattered but no matter. I quit reading when I realized the book still assumed the existence of the ether. "Screw this," I thought. So I flipped off the science bit, kept to my computers, and carried on.

But here I was in the USA, land of opportunity and well-stocked libraries. Looking in the physics section I saw "The Feynman Lectures on Physics" sitting there, three volumes. I had a vague idea of who Feynman was, so I picked up the books and went straight to Volume 3, Chapter 1, Quantum Behavior. In the very first page he comes right out and says:
Things on a very small scale behave like nothing that you have any direct experience about. They do not behave like waves, they do not behave like particles, they do not behave like clouds, or billiard balls, or weights on springs, or like anything that you have ever seen. (...)
Because atomic behavior is so unlike ordinary experience, it is very difficult to get used to, and it appears peculiar and mysterious to everyone--both to the novice and the experienced physicist. Even the experts do not understand it the way they would like to, and it is perfectly reasonable that they should not, because all of direct human experience and human intuition applies to large objects. We know how large objects will act, but things on a small scale just do not act that way.
I felt a rush of enthusiasm reading this. It was so humble and visceral and honest. This was science in a way I had never seen before, simultaneously more rigorous and human. That first page alone drove a sledgehammer to my worldview and started rebuilding it. Perhaps childishly, I thought of the Hacker's Manifesto: "we've been spoon-fed baby food at school when we hungered for steak." I had just found one hell of a juicy stake. At one point Feynman asks students to imagine the various electromagnetic fields and waves in the classroom: coming from the earth's interior, carrying radio and TV signals, traveling from warm foreheads to the blackboard, and so on. Then he says:
Volume 2, pages 20-9 and 20-10I have asked you to imagine these electric and magnetic fields. What do you do? Do you know how? How do I imagine the electric and magnetic field? What do I actually see? What are the demands of the scientific imagination? Is it any different from trying to imagine that the room is full of invisible angels? No, it is not like imagining invisible angels. It requires a much higher degree of imagination (...). Why? Because invisible angels are understandable. (...) So you say, "Professor, please give me an approximate description of the electromagnetic waves, even though it may be slightly innacurate, so that I too can see them as well as I can see almost-invisible angels. Then I will modify the picture to the necessary abstraction."
I'm sorry I can't do that for you. I don't know how. I have no picture of this electromagnetic field that is in any sense accurate. (...) So if you have some difficulty in making such a picture, you should not be worried that your difficulty is unusual.
Surely you're joking - you don't know?? I could hardly believe what I was reading. I had been hoping for a better explanation - a masterful analogy of weights on springs that would allow me to really understand physics. Instead, here was a Nobel laureate telling me that he didn't really understand it either - not in the definite, make-believe fashion of high school science. Feynman lifted the veil for me - all my sanitized textbooks and uninspired teachers presented science with finality and devoid of context, as if the gods had handed down a few scientific models to us. Analogies that were meant to "help understand" reality had in fact supplanted it; it was not simplification, but a gross distortion of what science really is. This fake teaching would never say that atomic behavior is "peculiar and mysterious" because "human intuition applies to large objects." No, its entire aim was to pretend that science is not mysterious.
Feynman embraces the whole of science: its beauty, its methods, the history and relationships of its ideas, how our minds react to it, and above all how it stands before the ultimate judge, nature. He's at once fiercely empirical yet mindful of the crucial human context surrounding scientific ideas. The lectures are not only great technical writing but also a deep look into how we think about the world, into reason and the nature of knowledge. Of course, much of the work is to be done with paper, pencil, and math. Back then I didn't even know calculus, so I couldn't really follow all the equations. But the books still gave me what I was looking for, and then some.
Now I have an undergrad in math, which puts me roughly in the 18th century, but better equipped to learn on my own. Some day I hope to take time off and hit physics again. If you want to read more of his stuff, Feynman wrote an insightful essay on engineering and there's the classic Cargo Cult Science, both online. Amazon has the lectures along with other books, and so might your local library. :)